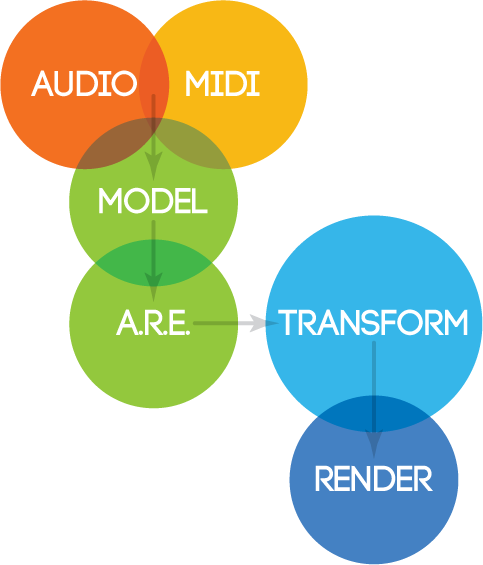
Isomer is a suite of software that produces an abstracted representation of the characteristic trends present in musical language through the analysis of symbolic or audio input. Isomer uses this abstracted representation to execute query and transformation algorithms, with the ultimate goal of generating of new/hybrid materials.
Isomer assembles a unified model from raw analysis data (symbolic and/or audio) and populates a single (or multiple) database(s) with observed and interpreted feature data representations. Multiple model abstractions can exist simultaneously in discrete databases, a key feature of Isomer that encourages the emergence of a desired representation schema for the musical model. Model data is separated into four musical components: melody, harmony, rhythm and timbre depending on source availability.
Data Representation Overview
Isomer provides normalized storage of feature data in a Cartesian coordinate (grid) format. This allows input from various sources to combine in a single model representation suitable for further analysis and abstraction.
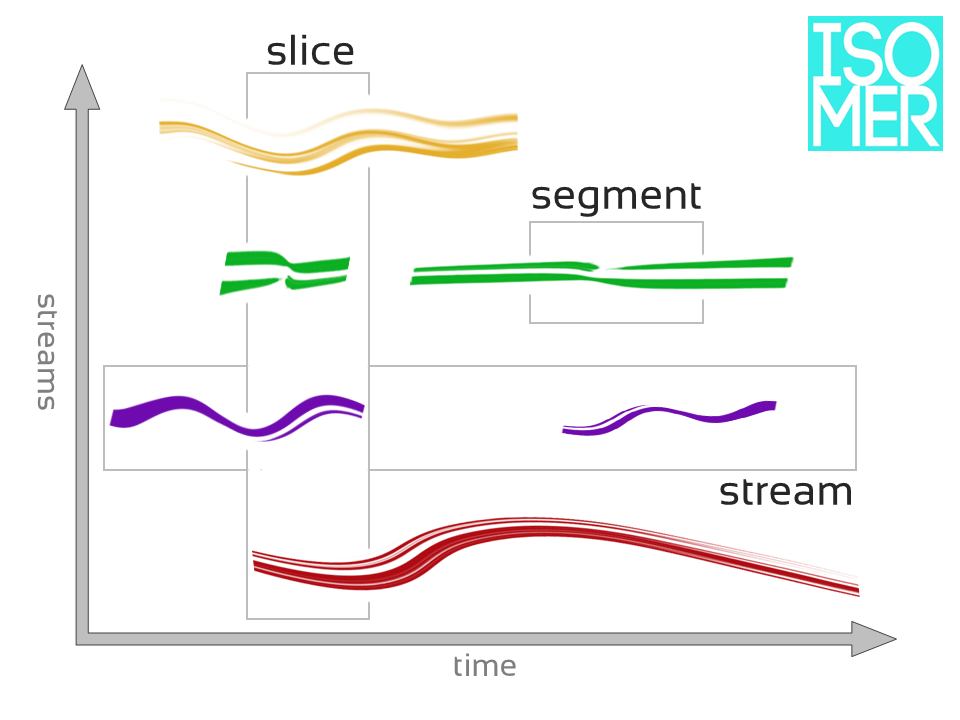
Cartesian Grid Format
Horizontal Axis
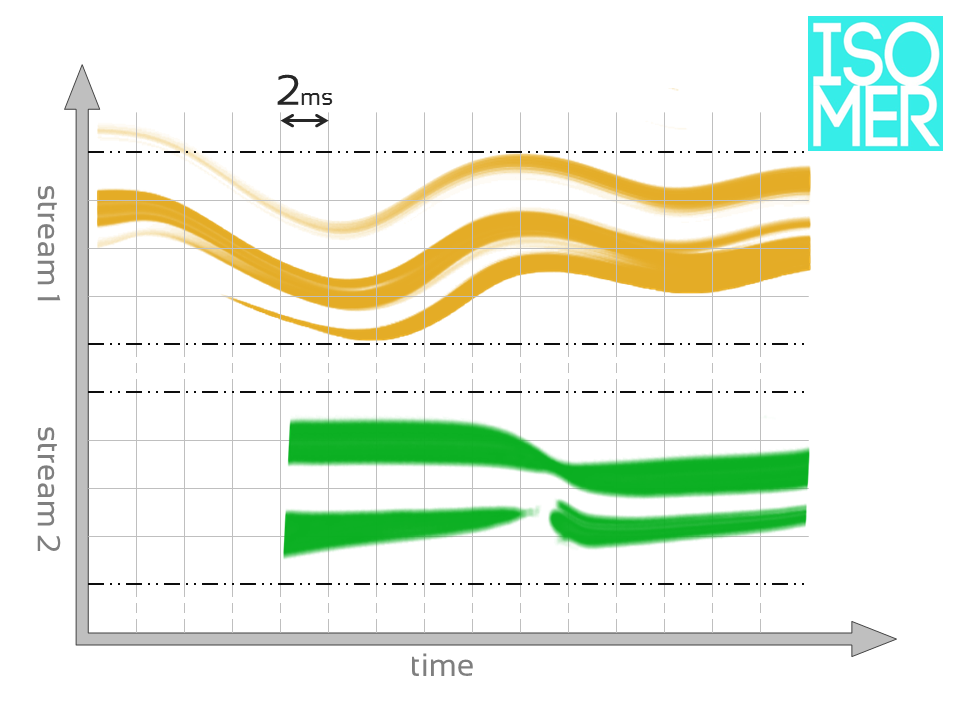
The horizontal (X) axis represents time with sampled data appearing at a regular, user-defined time interval (default = 2 ms). Each vertical column of data is called a slice.
Why is 2ms the default Slice window?
2ms is the smallest time interval at which humans can detect multiple transients and allows for complete capture of MIDI files with resolution of 30bpm @ 960ppq (or 60bpm @ 480ppq).
Vertical Axis
The vertical (Y) axis contains individual streams (type is dependent on input). Each stream forms a horizontal row that is further divided into four sub-stream categories: melody, rhythm, timbre and harmony.
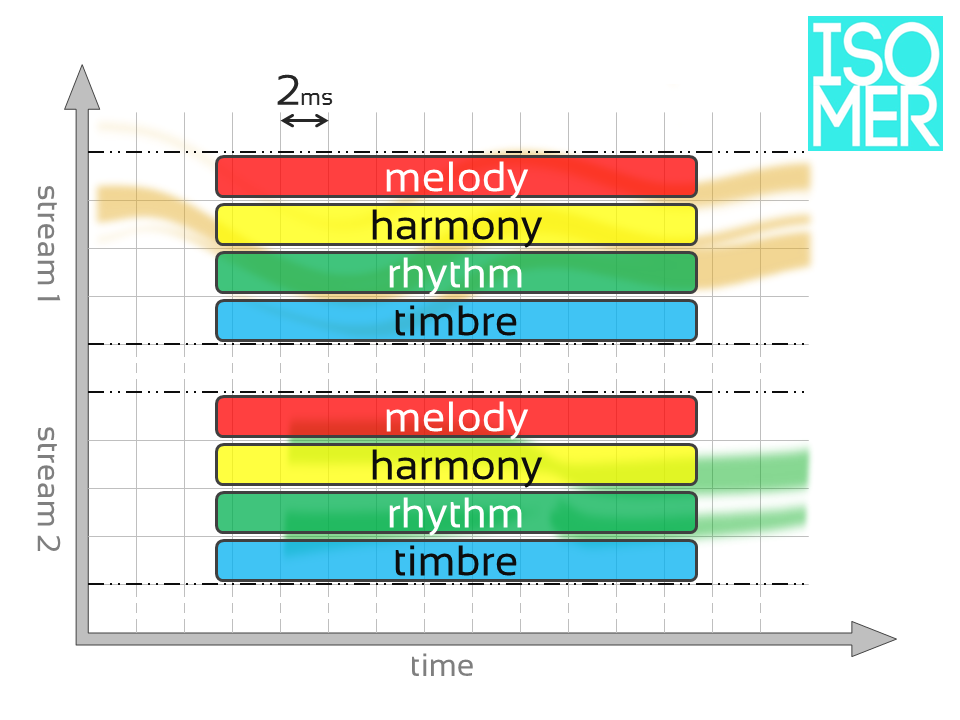
Each grid point contains multidimensional data for each of the stream sub-categories in time at a resolution defined by the user.
Observed and Extrapolated Data Fields
The source of input data (audio or symbolic) is determined at the time of model creation. Once the model is generated, the original format (audio or symbolic) of the raw data is no longer an issue, although input format can limit the parameters available (i.e. symbolic input contains no texture data).
Regardless of the input format, Isomer attempts to collect data without interpretation using the most accurate methods of analysis available. These data fields are treated as empirical observations. However, during model creation Isomer also calculates additional parameters to better prepare the data for use in a musical context. These are extrapolated data fields.
The grid format described above requires two coordinates: stream/sub-stream (Y) and a series of analysis windows (X). Each point in the grid contains data for the following parameters:
* indicates an extrapolated data field
- Melody
- Pitch (hertz, midi)
- Pitch IR *
- IR Equity *
- Proximity Equity *
- Registral Return *
- Rhythm
- Band (describes Bark Scale freq range where onset is detected)
- Intensity (percentage, velocity)
- Onset Equity *
- Timbre
- RMS
- Spectral Stability
- Spectral Flatness
- MFCC (13)
- Harmony
- Pitches (hertz, midi, intensity)
- Average Chroma
- Total Pitches *
- Tension *
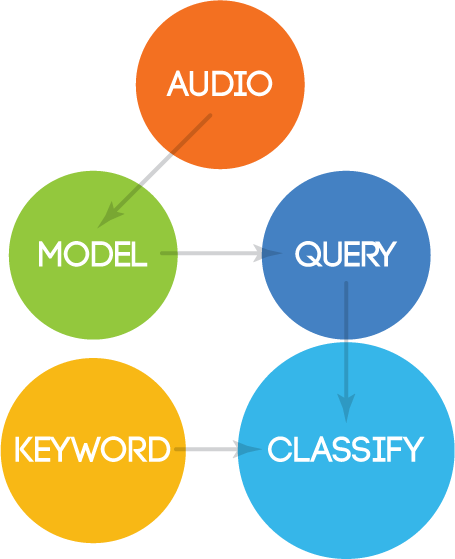
Multi-Event Query Parameters
Querying musical data in Isomer allows users to mine the models for musically relevant trends. The user supplies coordinates as time and stream/sub-stream ranges. This input is translated into the matrix coordinates (as defined by the model) before the query is executed.
The interface returns the results as time points (X-axis) and streams/sub-streams (Y-axis) for a given model and allows on-demand calculation of any/all of the following data for any grid coordinates or range of coordinates:
- Melody
- Registral Direction
- Registral Return
- Proximity Ratio
- Interval Range
- Melodic Accent
- Rhythm
- Temporal Direction
- Temporal Instability
- IOI Range
- NPVI IOI
- NPVI Duration
- Agogic Accent
- Syncopation
- Timbre
- Texture Fingerprint
- Dynamic (Timbre) Accent
- Harmony
- Tension Direction
- Tension Instability
- Average Tension
Increasing Understanding Through Multiple Perspectives
Isomer extrapolates parameters in addition to the observed data only after window-based quantization takes place. The interpretation that necessarily occurs during quantization can create desirable variations in the resulting model representation. By generating several models from the same source input with varying window sizes, Isomer can create multiple representations of a single input source.
The power of implementing a series of interpreted abstractions is that the raw data can be represented multiple times at varying depths from the original (raw) observations regardless of the model input format, giving the user a variety of ways to view and examine the model. For symbolic input, this provides a useful way to control the level of detail captured in the model. In the case of audio input, the user can find the most appropriate representation for a specific input file; a problem inherent in the musical analysis of raw audio.
For example, determining the location of event onsets, “beats”, or perceptual pulse points may require a high-resolution view of feature data, while the detection of more expansive musical elements like harmonic rhythm may benefit significantly from a more general reduction of the raw DSP data.
In conjunction with the Isomer’s query function, multiple versions of the abstraction layer can exist simultaneously in discrete databases. This design is a key feature of Isomer that encourages the emergence of a desired representation schema, as dictated by the specific task the user has in mind.